Reference Success Criteria
By defining clear, feasible objectives and combining objective data with user experience assessment, evaluation can be made more rigorous and less biased. The following criteria are reference standards for speech models and may be adapted to specific use cases.- Task Completion Assesses the model’s ability to accurately convert input text into speech. Word Error Rate (WER) is a key metric, computed by converting synthesized speech into text via Automatic Speech Recognition (ASR), then comparing it against the reference text to count substitution, insertion, and deletion errors.
- Voice Similarity Assesses the similarity between synthesized audio and a reference recording in terms of speaker characteristics. Similarity (SIM) is calculated by extracting embeddings from both synthesized and reference audio, then computing cosine similarity between the embeddings.
- Perceptual Quality Measures the perceived quality of synthesized audio. PESQ is a standard objective metric that compares the synthesized audio against a high-quality reference, approximating human auditory perception.
- Intelligibility Evaluates the degree to which synthesized speech can be understood. STOI is an established objective metric for intelligibility, quantifying how well listeners can comprehend sentence-level content.
-
Subjective Preference
Captures user perception of synthesized audio. Common approaches include ELO rating and Comparative MOS (CMOS):
- ELO Rating: Pairwise A/B tests are conducted, where listeners select preferred samples. Scores are updated using the ELO formula to reflect relative preference across models.
- CMOS: Listeners score the quality difference between two samples in A/B tests. Average scores across participants indicate relative performance.
- Instruction Compliance Assesses whether the model follows input constraints when generating speech, including emotion control and timbre specification. Evaluation can involve feature comparison with target instructions or subjective A/B testing.
- Cost Evaluates the economic feasibility of using the model, considering per-call costs and expected usage frequency.
- Latency Measures time efficiency from input to audio output. For streaming synthesis, first-packet latency is a key metric, defined as the interval from receiving the full input to generating the first playable audio frame.
Evaluation Scenarios
Speech models can be applied across various scenarios. To comprehensively evaluate performance, testing should consider behavior across different use cases.- Voice Cloning
- Multilingual Generation
- Cross-Lingual Synthesis
- Emotion Control
- Text-Driven Voice Creation
Results and Example Test Cases
MiniMax Speech-02 Objective Results
- Voice Cloning
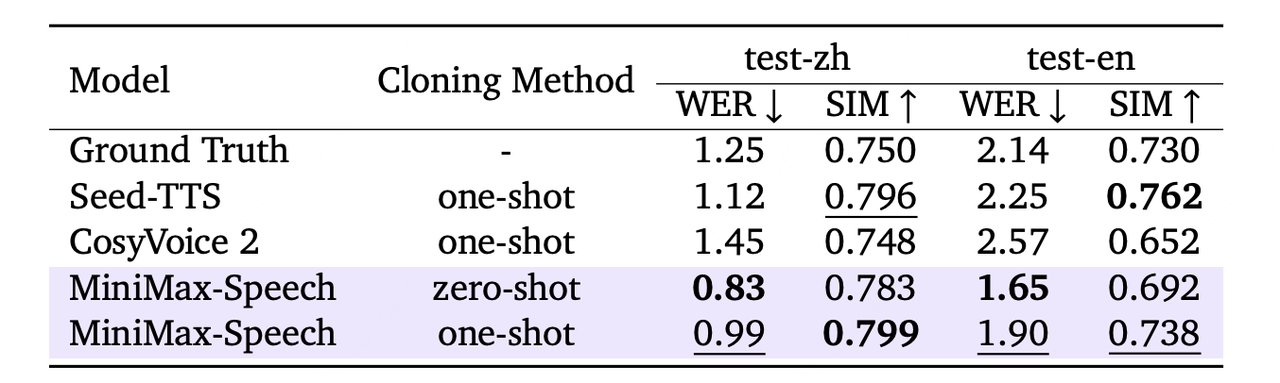
The MiniMax Speech-02 model achieves high-quality voice cloning with short reference samples and transcripts. Results in both Chinese and English show low WER and high SIM, indicating strong cloning fidelity.
- Multilingual Synthesis
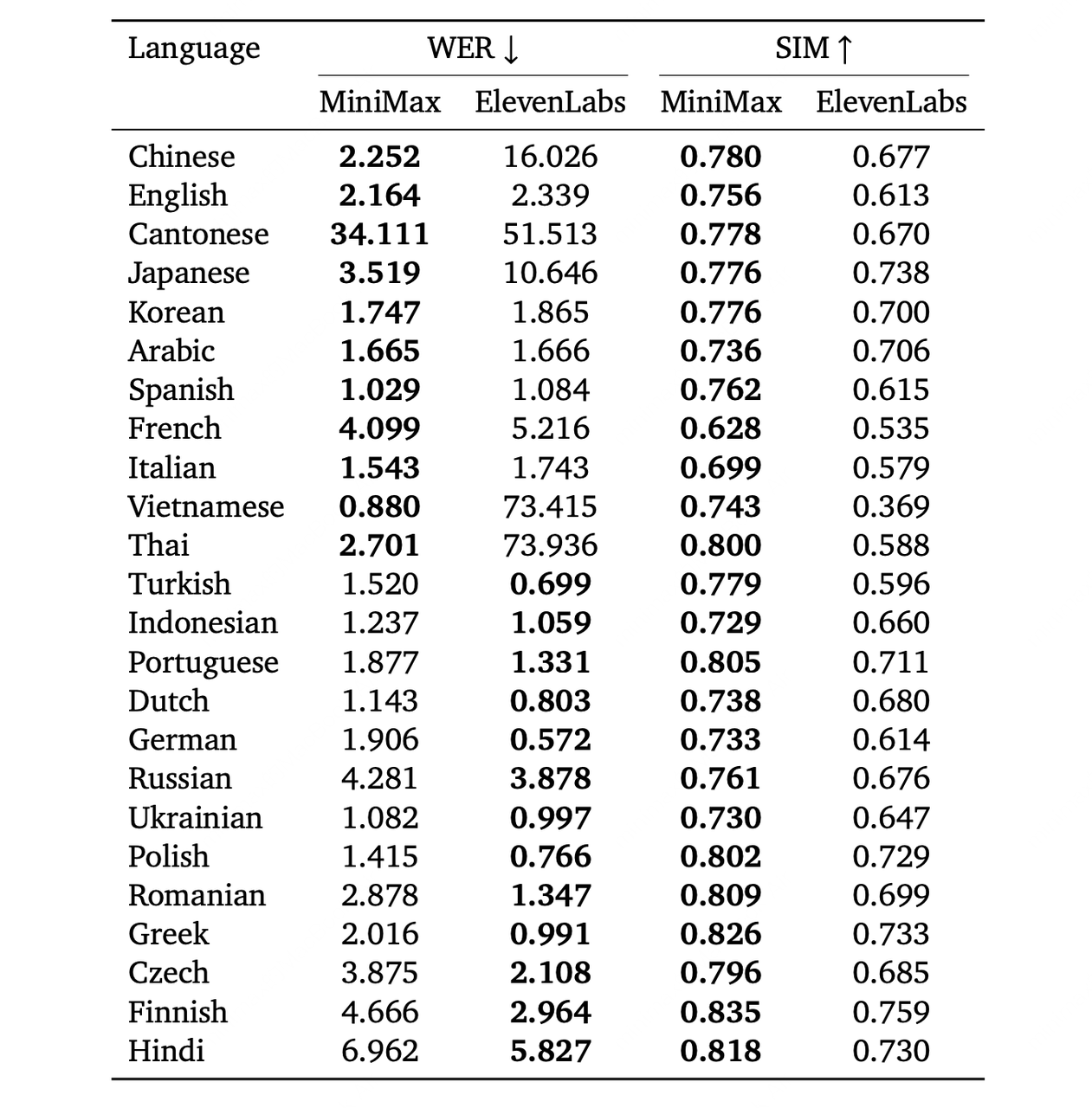
The MiniMax Speech-02 model supports 32 languages with high accuracy and strong similarity preservation.
- Cross-Lingual Synthesis
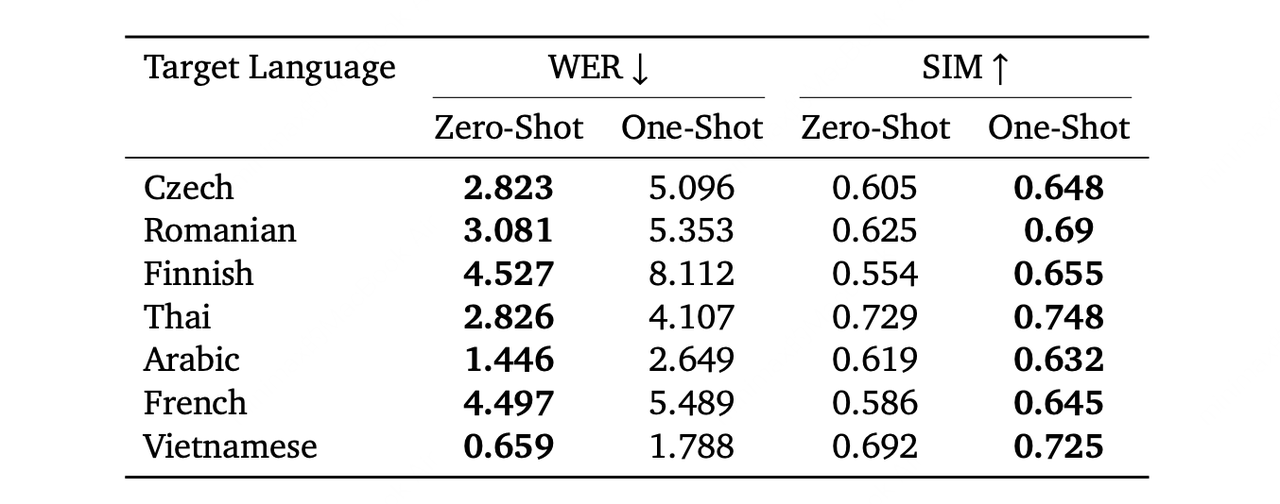
The MiniMax Speech-02 model demonstrates strong cross-lingual ability, generating speech in other languages from short audio clips. Experiments with Chinese as the source show zero-shot cloning has higher accuracy, while one-shot cloning yields better timbre similarity.
MiniMax Speech-02 Test Cases
- Voice Cloning
- Description: A Compelling and Persuasive Speaker Voice
- Source Audio
- Generated Audio
- Description: A Robotic Voice with Rich Bass Resonance and Spatial Presence
- Source Audio
- Generated Audio
- Description: A Compelling and Persuasive Speaker Voice
- Multilingual Capabilities
- Thai
- Source Audio
- Generated Audio
- Vietnamese
- Source Audio
- Generated Audio
- Thai
- Cross-Lingual Capabilities
- English + Spanish
- Source Audio (English)
- Generated Audio
- Japanese + Korean
- Source Audio (Japanese)
- Generated Audio
- English + Spanish
- Emotion Control
- Surprised
- Source Audio
- Generated Audio
- Sad
- Source Audio
- Generated Audio
- Surprised
- Voice Design
- Example1
- Prompt: A stereotypical, larger-than-life gruff pirate captain, characterized by a deep, extremely gravelly, and raspy timbre with rough, stylized articulation that includes piratical clichés and exaggerated ‘R’ sounds. His speech is loud, boisterous, and declamatory, delivered with a swaggering, rolling cadence, a low, rumbling pitch, and punctuated by hearty exclamations or growls, conveying an intimidating, adventurous, and fiercely independent persona ideal for boasting, issuing gruff commands, or demanding treasure.
- Generated Audio
- Example2
- Prompt: Whispering sultry adult female, reminiscent of a femme fatale ASMR artist, characterized by soft, slightly breathy articulation and a slow, deliberate pace. Her low to mid-range pitch features a seductive, meandering intonation with downward glides and lingering vowels, while her warm, breathy, smooth, and husky timbre, often close-miked, creates an alluring, intimate, and mysterious atmosphere designed to entice and charm the listener.
- Generated Audio
- Example3
- Prompt: A classic, high-energy male announcer voice. The pace is rapid and almost breathless, with a loud, projecting delivery designed to grab attention.The pitch is dynamic and generally in a higher range, using exaggerated, rising intonation to build excitement, urgency, and a highly persuasive, hard-sell tone.
- Generated Audio
- Example4
- Prompt:An English-speaking man terrified of going insane. His voice is generally low-pitched, but with a wide and unnatural range of variation. The overall pace of his speech is slow, yet highly variable, punctuated by frequent pauses of inconsistent lengths that create a sense of urgency. His voice is torn and hoarse, trembling with fear.
- Generated Audio
- Example1