The Real Agent Alignment Problem: Benchmarks or Reality?
f you’ve worked with LLM Agents, you’ve felt this pain: the same model can feel brilliant in one framework and useless in another. An agent might crush a tool-use leaderboard but fail spectacularly at a simple, real-world task. This gap between benchmark performance and practical usability is one of the biggest challenges in the field. When we designed M2, we knew we had to tackle this problem head-on. This led us to two core, and sometimes conflicting, objectives:- Excel on Open-Source Benchmarks. Benchmarks are essential for measuring “pure” capabilities. A benchmark like BrowseComp, for instance, tests for sophisticated search skills. While users will rarely ask a question as contrived as, “Find the paper where the third letter of the nth author’s name is ‘x’,” a model that can solve it proves it has strong foundational abilities.
- Generalize Robustly to the Real World. This is the harder, more important part. A great agent must perform reliably across unfamiliar tools, IDEs/CLIs, agent scaffolding, and user setups. It can’t be a one-trick pony; it needs to generalize.
The Need for Interleaved Thinking
Early in the project, we hit a frustrating wall. Agent performance was inconsistent, and we struggled to diagnose why. After many discussions, especially with Professor @Junxian He and @Wenhu Chen, we arrived at our first major conclusion: Agents require Interleaved Thinking. This means that an agent’s internal monologue—its “thinking”—can and should happen at any point during a task, not just once at the beginning like a standard reasoning model. This design is critical for two reasons:- Maintaining Focus on Long-Horizon Tasks. Complex agent tasks have extremely long contexts. A single thought process at the start isn’t enough to maintain instruction-following and coherence.
- Adapting to External Perturbations. This is the crucial difference. Agent tasks introduce constant, unpredictable perturbations from the outside world (i.e., tool outputs). The model must be robust enough to handle these perturbations, diagnose errors, and extract useful information. The “thinking” process allows the model to constantly re-evaluate and adapt to new information from the environment.
“Pro Tip for M2 Users: Because M2 relies on Interleaved Thinking, its context is its memory. For best performance, you must retain the full session history, including the thinking steps. We’ve noticed that much of the community feedback about performance gaps stems from accidentally discarding this vital context, which is a common practice with simpler reasoning models.”
True Generalization is About Perturbation
Our initial theory was simple: tool scaling is agent generalization. We started with a minimal set of tools (a Python interpreter, search engine, a browser) to build a baseline of tool-calling capability. The roadmap was clear: scale up the number and variety of tools, and the agent’s ability to generalize to unseen tools would naturally follow. At first, this worked. Our benchmark scores climbed to respectable levels. But as we dug deeper, we realized we were solving the wrong problem. The model aced the tests, but if we changed the environment even slightly—like swapping to a different scaffolding framework—its performance would plummet. We were still far from our goal of a “practically useful” model. This led to our second, more profound realization: Agent generalization is not just about adapting to new tools; it’s about adapting to perturbations across the model’s entire operational space.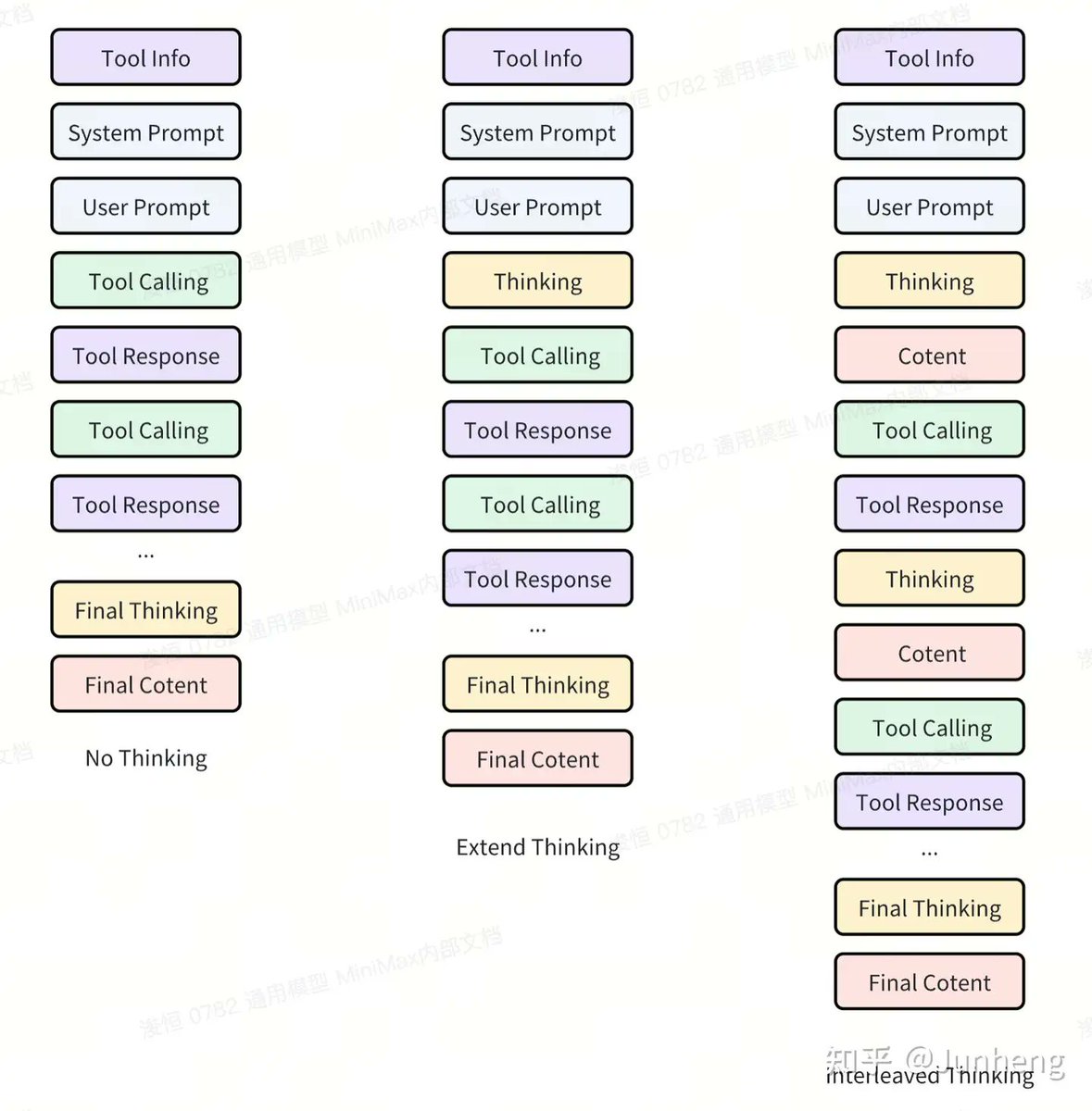 This sounds abstract, so let’s break it down. Think about everything that can change in a single agent task:
This sounds abstract, so let’s break it down. Think about everything that can change in a single agent task:
- The Tool Info and available toolset.
- The System Prompt defining the agent’s persona and rules.
- The User Prompt and its specific goal.
- The Environment itself (files, codebases, APIs).
- The Tool Responses returned at each step. Our old “tool scaling” approach only addressed the first item. It ignored perturbations in all the other parts of the process. Armed with this new understanding, our team built a comprehensive data pipeline designed for full-trajectory generalization. The data it generates trains the model to be stable against perturbations at every step. The results have been incredibly encouraging. In internal tests, we threw obscure, “cold-start” scaffolding at M2—frameworks we’d barely considered—and its performance exceeded our expectations. Both its tool-calling and instruction-following abilities generalized beautifully.
What’s Next?
Our work on M2 taught us an immense amount about agents, generalization, and data, but it has opened up more questions than it answered. Many of our ideas are still on the whiteboard. In the coming months, we will be exploring these frontiers even more deeply, and we can’t wait to bring you the next generation of powerful and genuinely useful models.Getting Involved
- Use the Model: We sincerely hope you’ll put M2 to the test. You can access it through our official channels or find the open-sourced version to conduct your own research.
- Join Our Team: If these are the kinds of challenges that excite you, we’re hiring. We are always looking for passionate people to join us in the mission to build AGI. Please send us your resume!